

YoloV5实战:手把手教物体检测——YoloV5
【摘要】 目录摘要训练1、下载代码2、配置环境3、准备数据集4、生成数据集5、修改配置参数6、修改train.py的参数7、查看训练结果测试摘要YOLOV5严格意义上说并不是YOLO的第五个版本,因为它并没有得到YOLO之父Joe Redmon的认可,但是给出的测试数据总体表现还是不错。详细数据如下:YOLOv5并不是一个单独的模型,而是一个模型家族,包括了YOLOv5s、YOLOv5m、YOLO…
摘要YOLOV5严格意义上说并不是YOLO的第五个版本,因为它并没有得到YOLO之父Joe Redmon的认可,但是给出的测试数据总体表现还是不错。详细数据如下:
点击并拖拽以移动
YOLOv5并不是一个单独的模型,而是一个模型家族,包括了YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x、YOLOv5x+TTA,这点有点儿像EfficientDet。由于没有找到V5的论文,我们也只能从代码去学习它。总体上和YOLOV4差不多,可以认为是YOLOV5的加强版。
项目地址:GitHub - ultralytics/yolov5: YOLOv5 🚀 in PyTo ...

初学入门YOLOv5手势识别之制作并训练自己的数据集
随着短视频vlog时代的到来,自动驾驶技术、人脸识别门禁系统、智慧视频监控、AI机器人等贴近人们日常生活的视频信息量的暴增,视频目标检测的研究具有无比的现实研究意义与未来行业潜力。视频是由一系列具有时间连续性和内容相关性的图像组成,所以关于视频目标检测的研究自兴起以来就是在经典的图像目标检测算法的基础上进行改进与创新的。软硬件设备的迭代更新,使得视频的流畅度也越来越高,几秒钟的视频画面便可包含高达两三百甚至上千张图像,而视频比单纯的图像包含更多的时间和空间信息,若直接用图像目标检测的方法对视频文件的内容逐帧检测,不仅忽视了视频的时空信息还会拖慢检测速度,难以达到实时的需求。如何利用视频提供的时空上下文信息提升检测的准确率、速度等性能,成为了各国研究人员的工作重点。目标检测 (Object Detection) 是计算机视觉和图像处理的一项分支技术,其主要任务是在一幅数字图像中正确识别出目标物体的位置并判断类别。目标检测算法需要框选出图片中的物体,并判断出框选出的物体是什么以及它是否可信。
得益于近年来 GPU 加速技术和深度学习技术的发展,使得如今基于深度学习的人脸检测能够达到高精度 ...

目标检测:单阶段YOLOv5及其相关应用介绍
(jk少女日常的yolov5检测识别)前言——背景简介(我和yolov5从此结缘)2021年底我和我们大学的班导师以及几位其他班级的同学一起开始了yolo系列视觉检测框架的学习,我们从项目的开始到现在也不过才几个月而已,其实我们虽然只是学习到了一些非常基础的视觉知识,比如我们大三选修的一门课程opencv视觉基础课程,虽然是计算机里边的视觉检测部分,但是对于我们这群视觉小白(好吧视觉小白其实是我自己)时过境迁,在AI方面我还是小学生,在社会的飞速发展中,视觉检测神经网络领域里边的Yolo早已经脱胎换骨从V1发展到了V5,并有各种衍生和优化版本譬如yolox和由中国科学院大学牵头搞出来的yolof。我们津津乐道它的名字是You only look once的简写,原意“你只看一遍”是为了区分看“两遍”的faster-rcnn等二阶段模型,其简写Yolo又寓意着另一句谚语”You only live once”,生命只有一次 ...

索尼微单编年史
作为资深的索粉,在每天顶礼索尼大法好的同时,是否知道索尼品牌是如何一路高歌,最终登顶销量榜首的呢?
今天我们就盘点下,从第一台微单“奶昔”开始,索尼是如何一步一步成为行业巨头的。
前传
2006年开始,索尼接手了柯尼卡美能达品牌 镜头卡口系统,开始研发数码单反相机,并沿用了美能达经典的“α”(阿尔法)品牌,并于同年发布了首款数码单反相机,α100。
索尼数码单反相机的开端α100
从2006年到2010年,索尼先后推出了数十款数码单反相机,α700,α200,α900,α850等等,几乎把好看的三位数字都用上了,期间还推出了惊艳的蔡司 Vario Sonnar T*镜头和机身防抖技术,为日后机身防抖功能的普及埋下了伏笔,同时也开启了欧洲老牌镜头和先进技术厂商的嫁接之路(可惜后来这些老家伙都去玩手机了)。
但索尼的单反之路并不顺利,相机的生产需要大量行业经验的积累和对摄影师充分的了解,作为一个年轻的相机品牌,索尼很显然是缺乏这些的。
开端
2010年 , 索尼正式出品了第一款无反相机——NEX-5,也就是历史闻名的“奶昔”系列,主打“将数码可更换镜头相机装入口袋”的理念 ...

上海交大提出CDNet:基于改进YOLOv5的斑马线和汽车过线行为检测
CDNet: A Real-Time and Robust Crosswalk Detection Network on Jetson Nano Based on YOLOv5
CDNet: 一个基于YOLOv5的在Jetson Nano上实时、鲁棒的斑马线检测网络
作者:Zheng-De Zhang, Meng-Lu Tan, Zhi-Cai Lan, Hai-Chun Liu, Ling Pei, Wen-Xian Yu
时间:Feb, 2022
期刊:Neural Computing & Applications, IF 5.6
一个神经网络在具体场景(斑马线检测)的应用,改进YOLOv5,提出多项tricks,数据集和复现代码开源!
摘要:
图1 图形摘要
在复杂场景和有限计算能力下实现实时、鲁棒的斑马线(人行横道)检测是当前智能交通管理系统(ITMS)的重要难点之一。有限的边缘计算能力和多云、晴天、雨天、雾天和夜间等真实复杂的场景同时对这项任务提出了挑战。本研究提出基于改进YOLOv5的人行横道检测网络(CDNet),实现车载摄像头视觉下快速准确的人行横道检测, ...

又来!项目如何改进YOLOv5?这篇告诉你如何修改让检测更快、更稳!!!
交通标志检测对于无人驾驶系统来说是一项具有挑战性的任务,尤其是多尺度目标检测和检测的实时性问题。在交通标志检测过程中,目标的规模变化很大,会对检测精度产生一定的影响。特征金字塔是解决这一问题的常用方法,但它可能会破坏交通标志在不同尺度上的特征一致性。而且,在实际应用中,普通方法难以在保证实时检测的同时提高多尺度交通标志的检测精度。
本文提出了一种改进的特征金字塔模型AF-FPN,该模型利用自适应注意模块(adaptive attention module, AAM)和特征增强模块(feature enhancement module, FEM)来减少特征图生成过程中的信息丢失,进而提高特征金字塔的表示能力。将YOLOv5中原有的特征金字塔网络替换为AF-FPN,在保证实时检测的前提下,提高了YOLOv5网络对多尺度目标的检测性能。
此外,提出了一种新的自动学习数据增强方法,以丰富数据集,提高模型的鲁棒性,使其更适合于实际场景。在100K (TT100K)数据集上的大量实验结果表明,与几种先进方法相比,本文方法的有效性和优越性得到了验证。
1介绍交通标志识别系统是ITS和无人驾驶系 ...

Hexo常用命令
npm install hexo -g //安装npm update hexo -g //升级hexo version //查看hexo的版本hexo init nodejs-hexo //创建nodejs-hexo 名字的本地文件hexo init nodejs-hexo //创建博客hexo init blog //初始化,生成文件夹为blogcd blog //进入blog文件夹npm install //安装依赖库hexo generate //生成一套静态网页hexo server //运行测试,浏览器打开地址,http://localhost:4000/hexo deploy //进行 ...
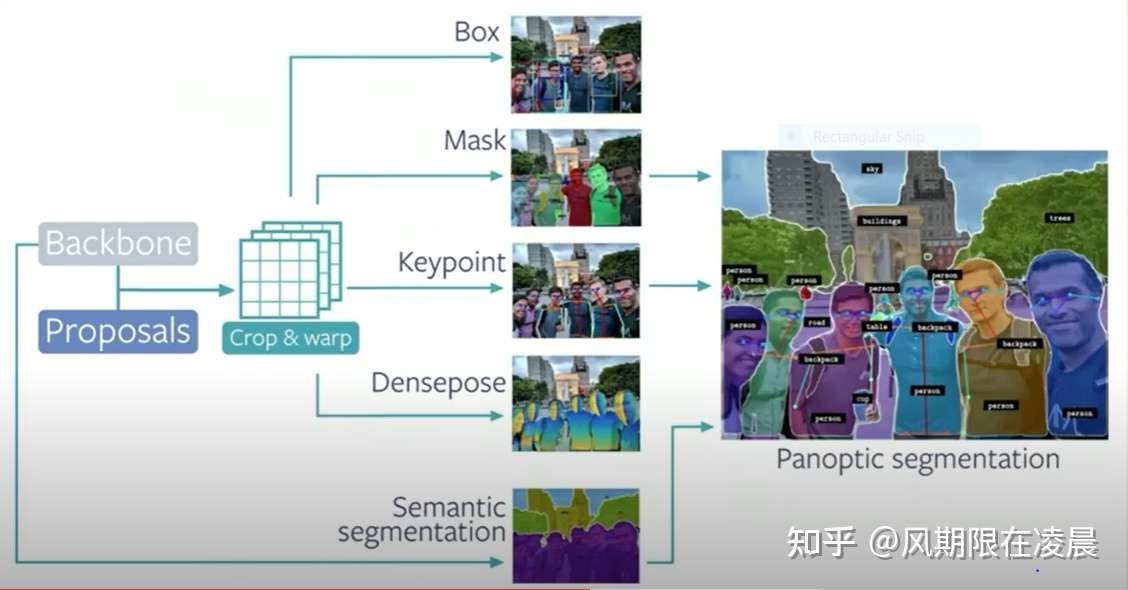
Detectron2实战案例
最近几个月有在跑detectron2和yolof但是遇到了很多困难,下次出一期安装detectron2的教程,其实可以搬运来自我自己的csdn写的内容也可以的
最近概况:最近在学习一些视觉的内容detectron2还有yolof,遇到了很多的问题,在csdn上基本上都可以寻找到相关答案的
https://blog.csdn.net/blink182007?type=blog “我的csdn主页”https://blog.csdn.net/blink182007/article/details/124222921?spm=1001.2014.3001.5502 “Detectron2安装踩坑记录(比较详细版)”
基本格式示例:python demo/demo.py –config-file configs/COCO-Detection/faster_rcnn_R_50_FPN_1x.yaml –input /images/1.jpg –output results –opt MODEL.WEIGHTS output/ ...

机器学习,深度学习,神经网络,深度神经网络之间有何区别?
首先,有必要对神经网络、深度学习、机器学习的概念做个简单描述。神经网络,该模型灵感来自动物的中枢神经系统,通常呈现为相互连接的“神经元°”,它可以对输入值通过反馈机制使得它们适应对应的输出。深度学习是神经网络的进阶版,它的基本思路与神经网络类似,但往往比神经网络有着更复杂的结构以及优化算法,是神经网络的纵向延伸,常见的模型有 CNN , RNN , LSTM 等。机器学习是一门多领域交又学科,渉及概率论°、统计学、逼近论、凸分析、算法复杂度理论等们学科。专们研究计算机怎样模拟或实现人类的学习行为,以获取新的识或技能,重新组织已有的知识结构使之不断改善自身的性能。接着,阐述神经网络、深度学习、机器学习的区别与联系。下面的图片很子地描述了这三者之间的关系:
在这之中,机器学习的涉及范围是最广的,神经网络次之,深度学习最小。机器学习包含了神经网络,神经网络中又包含了深度学习。机器学习专门研究计算机怎样模拟或实现人类的学习行为,而神经网络只是借助了动物的神经系统,只是用计算机实现人类行为的一种手段,因此,神经网络包含于机器学习。深度学习是神经网络的进阶版,只是在模型结构及优化算法等方面有不同 ...

Deep Fusion(深度融合)是什么?Deep Fusion有多优秀?
2019年10月29号的大半夜,苹果放出了iOS 13.2正式版的更新,顺手还更新了一波AirPods。之前发布会上提到的iPhone 11专属的Deep Fusion也正式上线,利用A13的神经网络引擎,可以在低光照环境下获得噪点更低的照片。
更新介绍讲的超级简单,但是小口袋知道这一切并不是那么简单!这篇文章讲讲Deep Fusion到底是个啥?用来干嘛的。
DeepFusion(深度融合)简介DeepFusion中文翻译应该叫深度融合,那么是怎么个融合法呢?看图:
简而言之,9图合成1图。DeepFusion采用的技术简单来说就是,当你按下快门,相机会先拍4张短时间曝光的照片,然后再以正常标准曝光拍4张,最后拍一张长曝光获取暗部细节,然后将这九张照片自动分析,选择其中解析力最高的部分进行合成。
在A13的加持下,合成速度只需要半秒到一秒半秒左右(其他处理器由于缺少对于ISP,无法实现该功能)。最终可以得到一张2400万像素的照片(2.6MB的HEIC格式,正常情况下的Smart HDR照片约为1.4MB HEIC格式)
不得不说,苹果这一 ...