目标检测:单阶段YOLOv5及其相关应用介绍


(jk少女日常的yolov5检测识别)
前言——背景简介(我和yolov5从此结缘)
2021年底我和我们大学的班导师以及几位其他班级的同学一起开始了yolo系列视觉检测框架的学习,我们从项目的开始到现在也不过才几个月而已,其实我们虽然只是学习到了一些非常基础的视觉知识,比如我们大三选修的一门课程opencv视觉基础课程,虽然是计算机里边的视觉检测部分,但是对于我们这群视觉小白(好吧视觉小白其实是我自己)时过境迁,在AI方面我还是小学生,在社会的飞速发展中,视觉检测神经网络领域里边的Yolo早已经脱胎换骨从V1发展到了V5,并有各种衍生和优化版本譬如yolox和由中国科学院大学牵头搞出来的yolof。我们津津乐道它的名字是You only look once的简写,原意“你只看一遍”是为了区分看“两遍”的faster-rcnn等二阶段模型,其简写Yolo又寓意着另一句谚语”You only live once”,生命只有一次。人生的面,见一面少一面,好好把握当下比什么都重要。

充满噱头的除了性能、名字外甚至还有作者本身,作者年初时宣布因为对技术滥用的担忧放弃视觉研究了,颇有高人之风。而且明明是个大胡子,个人网站却是满满粉色独角兽的萌妹风格。写的论文中,为了突出速度之快,甚至故意把图画到坐标轴外面去了。
机器视觉任务,常见的有分类、检测、分割。而Yolo正是检测中的佼佼者,在工业界,Yolo兼顾精度和速度,往往是大家的首选。
实际效果
V5的效果也是非常不错,这里给到官方模型的一些数据:



其实,yolov4刚出来的时候,大家还对名字争议了一番。毕竟原作者已经弃坑,新作看上去又是一个trick集合。马上yolov5出现之后,似乎对v4的质疑就消失了,因为v5这个名字起的似乎更离谱了。这里就不讨论名字争议了。
原理
作为一阶段end2end的检测算法代表作,我们简单回顾一下Yolo从V1到V5的主要改进措施,当然backbone也一直在进化着。
v1: 划分网格负责检测,confidence loss
v2: 加入k-means的anchor,两阶段训练,全卷积网络
v3: FPN多尺度检测
v4: spp,mish激活函数,数据增强mosaic\mixup,giou损失函数
v5: 对模型大小灵活控制,hardswish激活函数,数据增强
v1/v2因为对小目标检测效果不佳,在v3中加入了多尺度检测。v3大概可以比作iphone界的iphone6,是前后代广受好评的大成者,至今仍活跃在一线,“等等党永远不亏”。Yolov4把整个流程中可能进行的优化都梳理和尝试了了一遍,并找到了各个排列组合中的最好效果。v5可以灵活的控制从10+M到200+M的模型,其小模型非常惊艳。
v3到v5的整体网络图相差不多,可以清晰的看到:模型从三个不同尺度分别对大小不同的物体有重点的进行检测。
细节:数据增强和预处理
由于模型需要图片尺寸相同,因此可以采用resize、padding resize和letterbox的方法。letterbox训练的时候不用,只是在推理时候用。数据增强(data augmentation)是提升模型泛化能力的重要手段。
传统数据增强方式有随机翻转、旋转、裁剪、变形缩放、添加噪声、颜色扰动等等。


Random Erasing Data Augmentation(随机擦除数据增强)


随机的删除图片中部分区域,增强模型的泛化能力。
RandAugment(随机增强)
随机增强的意思是提前列举出几种数据增强的方式,如下图所示:

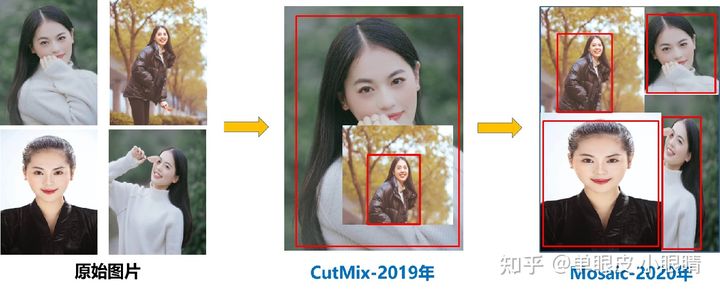
混合数据增强Mixup、Cutout、CutMix

Mixup是将两张图像以一定的概率凑到了一起,例如图中猫和狗各占一半,会显示一半像猫一半像狗;
Cutout是只一张图,但是随机选择一块区域进行丢弃;
CutMix则整合两种方法,仍然是两种图像各自占一定概率,然后丢弃一块区域的像素,用其中一张图像进行填充。
Mosaic Data Augmentation(马赛克数据增强)
那么问题来了——什么是马赛克数据增强呢?
该方法被应用到YOLO-V4当中扩充数据!
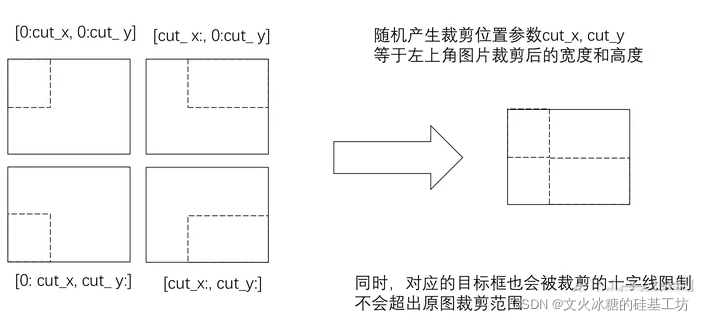
简言之马赛克数据增强就是把原来的四幅图组在一起——Mosaic借鉴了CutMix增强的方法,只不过本方法采用了4张图片,对其进行了随机裁剪、缩放、旋转等操作,合成1张图像,这种方式达到了如下的效果:


基本原理
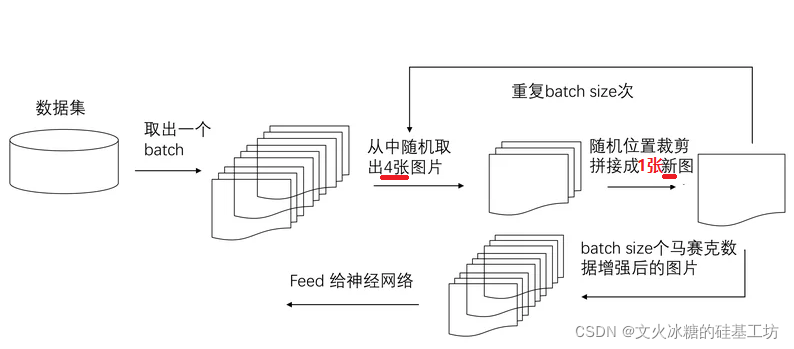
(1)扩充了数据集的数量
(2)增加了小样本的数量:把大样本随机放缩成了小样本,因此增加了小样本的数量。
(3)小样本更小:由于采用随机放缩,合并后,导致小样本的尺寸更小。
YOLO V5 - ultralytics代码解析
使能马赛克数据增强
超参数:hyp[‘mosaic’]
load_mosaic(self, index)
def load_mosaic(self, index)
{undefined
# 该函数会4张图片,先进行随机增强,然后合并成一张图片。
}
flip: 翻转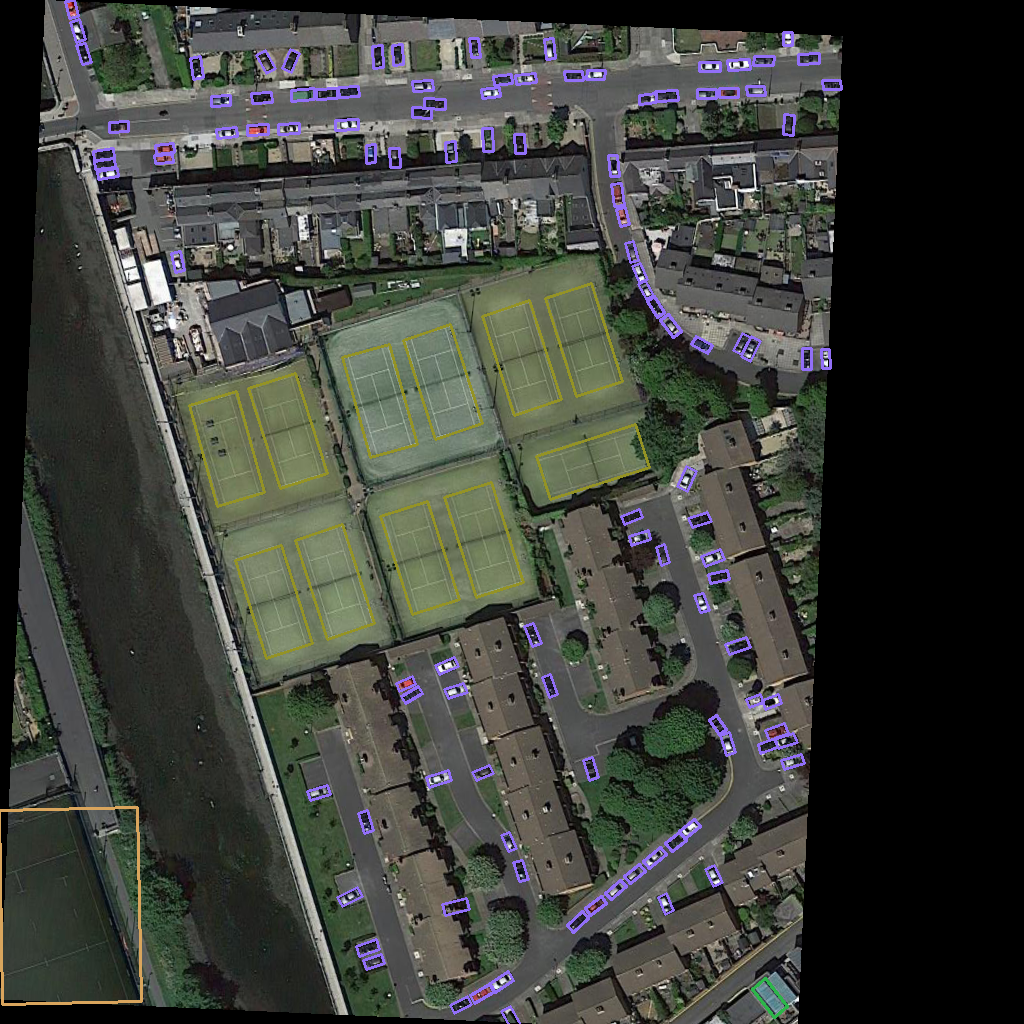
perspective:仿射变换
hsv augment:颜色变换
当然后面可以试试albumentations包里的方法。
获取anchor:k-means
早就在机器学习中学过最基础的聚类算法k-means,没想到第一次用上是在目标检测里。果然没有免费的午餐啊,在合适的地方用上合适的算法就好。k-means的两个关键超参数是k的选择和距离的选择,所以在Yolo中的k等于n_scale(尺度,一般为3)* anchor_per_scale (每个尺度的anchor,一般也为3)。V5做了一点小小的改进:训练时自动获取。
匹配anchor和网格
虽然讨论的时候,经常看见的都是改了哪些fancy的模型,真正写程序时比较困难的反而是这种数据前处理的pipeline。yolo的关键思想通过标记物体的中心点落在哪个网格里,就由这个网格负责检测,就是通过设置目标来实现的。
1)计算这张图片所有ground truth与每一个anchor的IOU,从而得到对每一个ground truth匹配最好的anchor id。可以根据真实框和锚矿的IOU或者长宽比来选择,v4与v5中做的改进是根据宽高比来进行anchor的匹配。
2)对每一个ground truth循环。找到这个anchor对应的尺度,和这个anchor对应的哪一个anchor。
3)模型最终输出的是三个尺度,每个尺度下每个网格带下的三个anchor对应的box。所以将标记的box也要放置到对应的grid里,对应的是三个anchor里的哪一个。根据上面找到对应grid,对应anchor,将标记的box尺寸和class 信息设置到目标里,其他设置为0。
另外两个改进点,一个改进点是正样本增强。通过正样本的增强可以减轻正负样本的不均衡。另一个改进点是标注框对anchor的encoding(编码方式)。从v2中引入anchor以来,一直通过如下编码方式
为了解决网格的敏感性,v4的作者发现简单的编码方式就可以提高结果。
x = (logistic(in) * 2 - 0.5 + grid_x) / grid_width
y = …
w = pow( logistic(in)*2, 2) * anchor / network_width
h = …
模型主体
(来自dabai同学)
v5的模型通过类似EfficientNet的两个系数来控制模型的宽度和深度,在yaml文件的depth_multiple和width_multiple中调节。
Focus:是v5相对v4的改进。
CSPNet:跨阶段局部融合网络
PANet:之前FPN是把传统视觉任务的图像金字塔改进到了深度学习的特征金字塔,来自论文Path Aggregation Network for Instance Segmentation。
损失函数
Yolo的损失函数比较惊艳,通过损失函数的设定把目标检测任务转化为一个回归任务。
`def build_targets(p, targets, model):
# `***Build targets for compute_loss(), input targets(image,class,x,y,w,h)***`
``det = model.module.model[-1] if is_parallel(model) else model.model[-1] # Detect() module na, nt = det.na, targets.shape[0] # number of anchors, targets tcls, tbox, indices, anch = [], [], [], [] gain = torch.ones(7, device=targets.device) # normalized to gridspace gain ai = torch.arange(na, device=targets.device).float().view(na, 1).repeat(1, nt) # same as .repeat_interleave(nt) #将targets复制3份,每份分配一个anchor编号,如0,1,2. 也就是每个anchor分配一份targets。 targets = torch.cat((targets.repeat(na, 1, 1), ai[:, :, None]), 2) # append anchor indices
重要的代码块在build_targets内。
g = 0.5 # bias
# 这里off表示了5个偏移,原点不动,往右、往下、往左、往上。
# 其中坐标原点在图像的左上角,x轴往右(列),y轴往下(行)。
off = torch.tensor([[0, 0],
[1, 0], [0, 1], [-1, 0], [0, -1], # j,k,l,m
# [1, 1], [1, -1], [-1, 1], [-1, -1], # jk,jm,lk,lm
], device=targets.device).float() * g # offsets
for i in range(det.nl):
#det.anchors在导入model的时候就除以了步长,因此此时anchor大小不是相对于原图,而是相对于对应特征层的尺寸
anchors = det.anchors[i]
gain[2:6] = torch.tensor(p[i].shape)[[3, 2, 3, 2]] # xyxy gain
# Match targets to anchors
#这里主要是将gt的cx,cy,w,h换算到当前特征层对应的尺寸,以便和该层的anchor大小相对应
t = targets * gain
if nt:
# Matches
#这个部分是计算gt和anchor的匹配程度
#即w_gt/w_anchor h_gt/h_anchor
r = t[:, :, 4:6] / anchors[:, None] # wh ratio
#这里判断了r和1/r与model.hyp['anchor_t']的大小关系,即只有不大于这个数,也就是说gt与anchor的宽高差距不过大的时候,才认为匹配。代码中 model.hyp['anchor_t']=4
j = torch.max(r, 1. / r).max(2)[0] < model.hyp['anchor_t'] # compare
# j = wh_iou(anchors, t[:, 4:6]) > model.hyp['iou_t'] # iou(3,n)=wh_iou(anchors(3,2), gwh(n,2))
#将满足条件的targets筛选出来。
t = t[j] # filter
# Offsets
#这个部分就是扩充targets的数量,将比较targets附近的4个点,选取最近的2个点作为新targets中心,新targets的w、h使用与原targets一致,只是中心点坐标的不同。
gxy = t[:, 2:4] # grid xy
gxi = gain[[2, 3]] - gxy # inverse
j, k = ((gxy % 1. < g) & (gxy > 1.)).T
l, m = ((gxi % 1. < g) & (gxi > 1.)).T
j = torch.stack((torch.ones_like(j), j, k, l, m))
t = t.repeat((5, 1, 1))[j] #筛选后t的数量是原来t的3倍。
offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j]
else:
t = targets[0]
offsets = 0
# Define
b, c = t[:, :2].long().T # image, class
gxy = t[:, 2:4] # grid xy
gwh = t[:, 4:6] # grid wh
gij = (gxy - offsets) #自己加的代码,方便查看gij的分布。
plot_gxy(gxy=gij, scale_i=i, size=gain, flag='gij') #自己编的代码,用于查看gij的分布。
gij = (gxy - offsets).long() #将所有targets中心点坐标进行偏移。
gi, gj = gij.T # grid xy indices
# Append
a = t[:, 6].long() # anchor indices
indices.append((b, a, gj, gi)) # image, anchor, grid indices
tbox.append(torch.cat((gxy - gij, gwh), 1)) # box
anch.append(anchors[a]) # anchors
tcls.append(c) # class
return tcls, tbox, indices, anch`
下图是20x20的特征图上的gij的分布示意图,从图中可以看出每个targets都扩充了2个临近的targets。关于为什么扩充,我还没理解,有知道的网友欢迎留言。另外,知乎网友Ancy贝贝的理解是:之前通过筛选,去掉了一些匹配不上anchor的gt,本来正样本就比负样本少很多,经过筛选,少得更多了,所以每个gt扩充2个出来,增加正样本比例。

# Regression
pxy = ps[:, :2].sigmoid() * 2. - 0.5
pwh = (ps[:, 2:4].sigmoid() * 2) ** 2 * anchors[i]
pbox = torch.cat((pxy, pwh), 1).to(device) # predicted box
giou = bbox_iou(pbox.T, tbox[i], x1y1x2y2=False, CIoU=True) # giou(prediction, target)
lbox += (1.0 - giou).mean() # giou loss
代码中的pxy对应bxy,ps[:, :2]对应txy。由此可知bxy的取值范围是[-0.5,1.5]。因此有可能偏移到临近的单元格内,但偏移不多,不知道作者是什么考虑的。

代码中的pwh对应bwh,anchors[i]对应Pwh。因此可知bwh的范围是[0,4]*Pwh。这和前面
j = torch.max(r, 1. / r).max(2)[0] < model.hyp[‘anchor_t’] # model.hyp[‘anchor_t’]=4 是一致的。
OBJECTNESS
tobj[b, a, gj, gi] = (1.0 - model.gr) + model.gr * giou.detach().clamp(0).type(tobj.dtype) # giou ratio
此处 tobj[b, a, gj, gi]用giou(真实的是ciou)取代1,代表该点对应置信度。为什么要用giou来代替,我也没想明白,有知道的网友欢迎留言。
其余的部分比较好理解,在此不再赘述。
附:
plot_gxy的代码:
def plot_gxy(gxy, scale_i, size, flag):
s = int(size[2].cpu().numpy())
ax = plt.subplot(111)
ax.axis([0, s, 0, s])
lxx = np.arange(0, s + 1, 1)
lxx = np.repeat(lxx, s + 1, axis=0)
lxx = lxx.reshape(s + 1, s + 1)
lyy = np.arange(0, s + 1, 1)
lyy = np.repeat(lyy, s + 1, axis=0)
lyy = lyy.reshape(s + 1, s + 1)
lyy = lyy.T
for i in range(len(lxx)):
plt.plot(lxx[i], lyy[i], color='k', linewidth=0.05, linestyle='-')
plt.plot(lyy[i], lxx[i], color='k', linewidth=0.05, linestyle='-')
for i in range(len(gxy)):
x1, y1 = gxy.cpu().numpy().T
plt.scatter(x1, y1, s=0.02, color='k')
ax = plt.gca() # 获取到当前坐标轴信息
ax.xaxis.set_ticks_position('top') # 将X坐标轴移到上面
ax.invert_yaxis()
plt.savefig("gxy_{}_{}.png".format(scale_i, flag))
plt.close()`
第一部分为box的损失函数,可以用过smoth L1损失函数计算xywh,也可以通过iou、giou、ciou等。类似的giou、diou和ciou都是在交并比iou的基础上发展而来的优化方法,解决了iou在两个候选框完全没有交集时,损失为0不可优化的状况。第二部分为有无物体的损失:yolo独特的设置了一个有无物体的confidence,目标中有的自然设置为1。预测的值用sigmoid转化为(0,1)的概率,然后计算binary cross entropy。第三部分为分类损失部分,虽然是多分类,也采用binary corss entropy。
同时,为了平衡不同尺度的输出,v5中对以上三部分加了人工痕迹比较明显的系数。
后处理
极大值抑制(nms)。分三个尺度进行检测,且分配不同的anchor,那么同一个物体有可能被多个尺度、anchor所检测到。所以通过极大值抑制来从中选择最佳的候选框。也有soft-nms、matrix-nms等改进方式可以试一试。
训练
训练过程就比较平平无奇了,可以添加如下技巧:梯度累积、遗传算法、EMA滑动平均、算子融合。
展望
检测之外,之后还可以继续拓展和优化的方向:
tensorrt推理加速
deepsort物体追踪,可以稳定视频中检测框的抖动
针对小目标分割patch检测,例如卫星遥感图像的改进you only look twice
多尺度scalable yolov4
代码如下:
Yolov5-pytorch
Yolov5-tensorflow
date: 2022-3-22 20:22:25
tags: 标签
categories: 分类