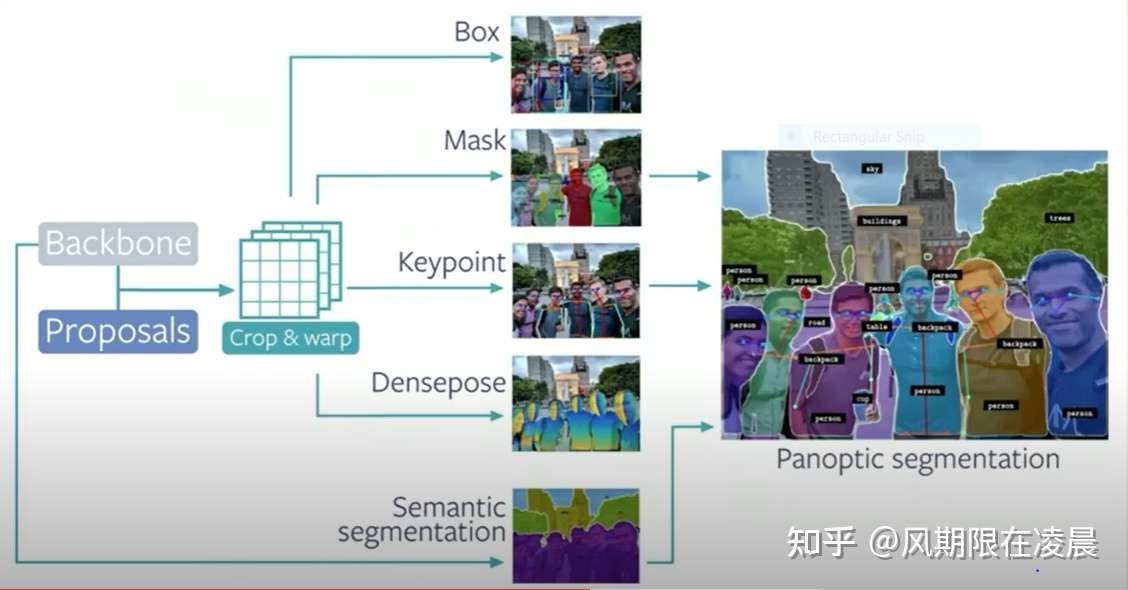
Detectron2实战案例
最近几个月有在跑detectron2和yolof但是遇到了很多困难,下次出一期安装detectron2的教程,其实可以搬运来自我自己的csdn写的内容也可以的
最近概况:
最近在学习一些视觉的内容detectron2还有yolof,遇到了很多的问题,在csdn上基本上都可以寻找到相关答案的
https://blog.csdn.net/blink182007?type=blog “我的csdn主页”
https://blog.csdn.net/blink182007/article/details/124222921?spm=1001.2014.3001.5502 “Detectron2安装踩坑记录(比较详细版)”
基本格式示例:python demo/demo.py –config-file configs/COCO-Detection/faster_rcnn_R_50_FPN_1x.yaml –input /images/1.jpg –output results –opt MODEL.WEIGHTS output/model_0049999.pth
python demo/demo.py –config-file configs/COCO-Detection/faster_rcnn_R_50_FPN_1x.yaml –input images/1.jpg –output results 可以但是没有结果
我的detectron2模型本地存储地址”E:\anacondalib\detectron2-master\detectron2-master\configs\COCO-Detection\retinanet_R_50_FPN_3x.yaml”
参考文献来源:
参考来自博客网站: https://blog.csdn.net/winorlose2000/article/details/112549795 “(82条消息) Detectron2 快速开始,使用 WebCam 测试_GoCodingInMyWay的博客-CSDN博客”
模型137849600/model_final_f10217.pkl下载来自Modelzoo网站:detectron2/MODEL_ZOO.md at main · facebookresearch/detectron2 (github.com) https://github.com/facebookresearch/detectron2/blob/main/MODEL_ZOO.md “137849600/model_final_f10217.pkl”
Python demo/demo.py –config-file configs/COCO-Detection/faster_rcnn_R_50_FPN_3x.yaml –webcam –output results –opt MODEL.WEIGHTS models/model_final_280758.pkl 实时检测失败
Python demo/demo.py –config-file configs/COCO-Detection/faster_rcnn_R_50_FPN_3x.yaml –input images/4.jpg –output results –opt MODEL.WEIGHTS models/model_final_280758.pkl
Python demo/demo.py –config-file configs/LVISv1-InstanceSegmentation/mask_rcnn_R_50_FPN_1x.yaml –input images/5.jpg –output results –opt MODEL.WEIGHTS models/model_final_571f7c.pkl 失败
“E:\anacondalib\detectron2-master\detectron2-master\configs\COCO-InstanceSegmentation\mask_rcnn_R_50_FPN_1x.yaml”
“E:\anacondalib\detectron2-master\detectron2-master\configs\LVISv1-InstanceSegmentation\mask_rcnn_R_50_FPN_1x.yaml”
检测代码和实例
1.1 普通目标检测:
Python demo/demo.py –config-file configs/COCO-Detection/faster_rcnn_R_50_FPN_3x.yaml –input images/1.jpg –output results –opt MODEL.WEIGHTS models/model_final_280758.pkl
成功语句 普通目标检测√
2.1 关键点检测:
Python demo/demo.py –config-file configs/COCO-Keypoints/keypoint_rcnn_R_50_FPN_3x.yaml –input images/7.jpg –output results –opt MODEL.WEIGHTS models/model_final_a6e10b.pkl 关键点检测成功√(”E:\anacondalib\detectron2-master\detectron2-master\configs\COCO-Keypoints\keypoint_rcnn_R_50_FPN_3x.yaml”
)(model_final_a6e10b.pkl)
3.1 语义分割实例:
Python demo/demo.py –config-file configs/COCO-PanopticSegmentation/panoptic_fpn_R_50_3x.yaml –input images/8.jpg –output results –opt MODEL.WEIGHTS models/model_final_c10459.pkl 语义分割实例成功√
(”E:\anacondalib\detectron2-master\detectron2-master\configs\COCO-PanopticSegmentation\panoptic_fpn_R_50_3x.yaml”)
(model_final_c10459.pkl)
4.1城市街道平面图实例
Python demo/demo.py –config-file configs\Cityscapes\mask_rcnn_R_50_FPN.yaml –input images/13.jpg –output results –opt MODEL.WEIGHTS models/model_final_af9cf5.pkl
5.1实时摄像头目标侦测
Python demo/demo.py –config-file configs/COCO-Detection/faster_rcnn_R_50_FPN_3x.yaml –webcam –output results –opt MODEL.WEIGHTS models/model_final_280758.pkl
(成功)
对于报错ERROR——File “demo/demo.py”, line 141, in
assert args.output is None, “output not yet supported with –webcam!”

将这一行注释掉即可
参考来自:(82条消息) Detectron2 快速开始,使用 WebCam 测试_GoCodingInMyWay的博客-CSDN博客
6.1实时语义分割检测
Python demo/demo.py –config-file configs/COCO-PanopticSegmentation/panoptic_fpn_R_50_3x.yaml –webcam –output results –opt MODEL.WEIGHTS models/model_final_c10459.pkl
(成功)
跑YOLOF的相关内容:
训练命令为:
***\Python ./tools/train_net.py –num-gpus 1 –config-file ./configs/yolof_R_50_C5_1x.yaml –eval-only MODEL.WEIGHTS output/yolof/R_50_C5_1x/model_final.pth
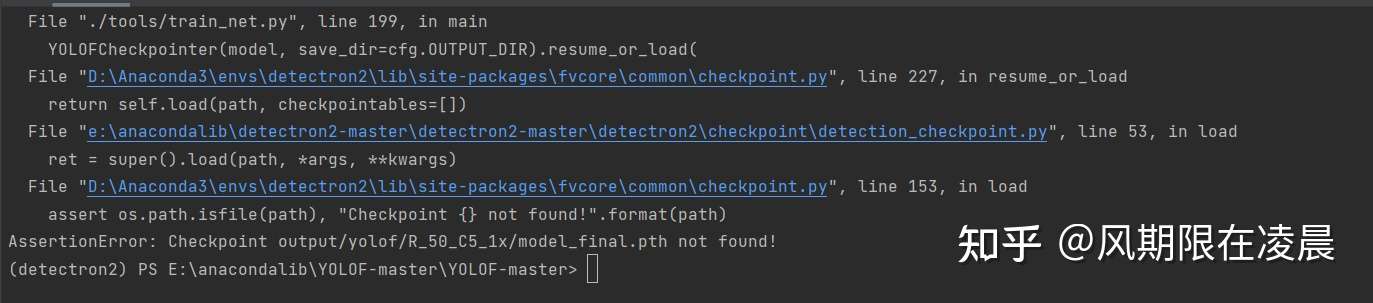
报错如下,需要注册coco2017数据集,自己标注数据,按照b站小鸡炖技术来训练文件,寻找出路和改进方向方法。标签平滑?

参考一下:一位b站深度学习up的训练命令如上图所示。
根据官方文档的内容——测试(test)命令如下:
python ./tools/train_net.py –num-gpus 1 –config-file ./configs/yolof_R_50_C5_1x.yaml –eval-only MODEL.WEIGHTS /path/to/checkpoint_file
运行过程如下(复制的比较多,可能有点长)
[04/23 11:13:46 detectron2]: Environment info:
sys.platform win32
Python 3.8.13 (default, Mar 28 2022, 06:59:08) [MSC v.1916 64 bit (AMD64)]
numpy 1.21.5
detectron2 0.5 @e:\anacondalib\detectron2-master\detectron2-master\detectron2
Compiler MSVC 192829923
CUDA compiler CUDA 11.1
detectron2 arch flags e:\anacondalib\detectron2-master\detectron2-master\detectron2_C.cp38-win_amd64.pyd; cannot find cuobjdump
DETECTRON2_ENV_MODULE
PyTorch 1.9.0+cu111 @D:\Anaconda3\envs\detectron2\lib\site-packages\torch
PyTorch debug build False
GPU available Yes
GPU 0 GeForce GTX 1650 (arch=7.5)
Driver version 457.63
CUDA_HOME C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.1
Pillow 9.0.1
torchvision 0.10.0+cu111 @D:\Anaconda3\envs\detectron2\lib\site-packages\torchvision
torchvision arch flags D:\Anaconda3\envs\detectron2\lib\site-packages\torchvision_C.pyd; cannot find cuobjdump
fvcore 0.1.5.post20220414
iopath 0.1.9
cv2 4.5.5
PyTorch built with:
- C++ Version: 199711
- MSVC 192829337
- Intel(R) Math Kernel Library Version 2020.0.2 Product Build 20200624 for Intel(R) 64 architecture applications
- Intel(R) MKL-DNN v2.1.2 (Git Hash 98be7e8afa711dc9b66c8ff3504129cb82013cdb)
- OpenMP 2019
- CPU capability usage: AVX2
- CUDA Runtime 11.1
- NVCC architecture flags: -gencode;arch=compute_37,code=sm_37;-gencode;arch=compute_50,code=sm_50;-gencode;arch=compute_60,code=sm_60;-gencode;arch=compute_61,code=sm_61;-gencode;arch=compute_70,code=sm_70;-gencode;arch=compute_75,code=sm_75;-gencode;arch=compute_80,code=sm_80;-gencode;arch=compute_86,code=sm_86;-gencode;arch=compute_37,code=compute_37
- CuDNN 8.0.5
- Magma 2.5.4
- Build settings: BLAS_INFO=mkl, BUILD_TYPE=Release, CUDA_VERSION=11.1, CUDNN_VERSION=8.0.5, CXX_COMPILER=C:/w/b/windows/tmp_bin/sccache-cl.exe, CXX_FLAGS=/DWIN32 /D_WINDOWS /GR /EHs
c /w /bigobj -DUSE_PTHREADPOOL -openmp:experimental -IC:/w/b/windows/mkl/include -DNDEBUG -DUSE_KINETO -DLIBKINETO_NOCUPTI -DUSE_FBGEMM -DUSE_XNNPACK -DSYMBOLICATE_MOBILE_DEBUG_HANDLE,
LAPACK_INFO=mkl, PERF_WITH_AVX=1, PERF_WITH_AVX2=1, PERF_WITH_AVX512=1, TORCH_VERSION=1.9.0, USE_CUDA=ON, USE_CUDNN=ON, USE_EXCEPTION_PTR=1, USE_GFLAGS=OFF, USE_GLOG=OFF, USE_MKL=ON, USE_MKLDNN=ON, USE_MPI=OFF, USE_NCCL=OFF, USE_NNPACK=OFF, USE_OPENMP=ON,
[04/23 11:13:46 detectron2]: Command line arguments: Namespace(config_file=’./configs/yolof_R_50_C5_1x.yaml’, dist_url=’tcp://127.0.0.1:49153’, eval_only=True, machine_rank=0, num_gpus=1, num_machines=1, opts=[‘MODEL.WEIGHTS’, ‘/path/to/checkpoint_file’], resume=False)
[04/23 11:13:47 detectron2]: Contents of args.config_file=./configs/yolof_R_50_C5_1x.yaml:
BASE: “Base-YOLOF.yaml”
MODEL:
WEIGHTS: “detectron2://ImageNetPretrained/MSRA/R-50.pkl”
RESNETS:
DEPTH: 50
OUTPUT_DIR: “output/yolof/R_50_C5_1x”
[04/23 11:13:47 detectron2]: Running with full config:
CUDNN_BENCHMARK: false
DATALOADER:
ASPECT_RATIO_GROUPING: true
FILTER_EMPTY_ANNOTATIONS: true
NUM_WORKERS: 2
REPEAT_THRESHOLD: 0.0
SAMPLER_TRAIN: TrainingSampler
DATASETS:
PRECOMPUTED_PROPOSAL_TOPK_TEST: 1000
PRECOMPUTED_PROPOSAL_TOPK_TRAIN: 2000
PROPOSAL_FILES_TEST: []
PROPOSAL_FILES_TRAIN: []
TEST:
- coco_2017_val
TRAIN: - coco_2017_train
GLOBAL:
HACK: 1.0
INPUT:
CROP:
ENABLED: false
SIZE:- 0.9
- 0.9
TYPE: relative_range
DISTORTION:
ENABLED: false
EXPOSURE: 1.5
HUE: 0.1
SATURATION: 1.5
FORMAT: BGR
JITTER_CROP:
ENABLED: false
JITTER_RATIO: 0.3
MASK_FORMAT: polygon
MAX_SIZE_TEST: 1333
MAX_SIZE_TRAIN: 1333
MIN_SIZE_TEST: 800
MIN_SIZE_TRAIN:
- 800
MIN_SIZE_TRAIN_SAMPLING: choice
MOSAIC:
ENABLED: false
MIN_OFFSET: 0.2
MOSAIC_HEIGHT: 640
MOSAIC_WIDTH: 640
NUM_IMAGES: 4
POOL_CAPACITY: 1000
RANDOM_FLIP: horizontal
RESIZE:
ENABLED: false
SCALE_JITTER:- 0.8
- 1.2
SHAPE: - 640
- 640
TEST_SHAPE: - 608
- 608
SHIFT:
SHIFT_PIXELS: 32
MODEL:
ANCHOR_GENERATOR:
ANGLES: - -90
- 0
- 90
ASPECT_RATIOS:
- 1.0
NAME: DefaultAnchorGenerator
OFFSET: 0.0
SIZES:
- 1.0
- 32
- 64
- 128
- 256
- 512
BACKBONE:
FREEZE_AT: 2
NAME: build_resnet_backbone
DARKNET:
DEPTH: 53
NORM: BN
OUT_FEATURES:
- res5
RES5_DILATION: 1
WITH_CSP: true
DEVICE: cuda
FPN:
FUSE_TYPE: sum
IN_FEATURES: []
NORM: ‘’
OUT_CHANNELS: 256
KEYPOINT_ON: false
LOAD_PROPOSALS: false
MASK_ON: false
META_ARCHITECTURE: YOLOF
PANOPTIC_FPN:
COMBINE:
ENABLED: true
INSTANCES_CONFIDENCE_THRESH: 0.5
OVERLAP_THRESH: 0.5
STUFF_AREA_LIMIT: 4096
INSTANCE_LOSS_WEIGHT: 1.0
PIXEL_MEAN:
- 103.53
- 116.28
- 123.675
PIXEL_STD: - 1.0
- 1.0
- 1.0
PROPOSAL_GENERATOR:
MIN_SIZE: 0
NAME: RPN
RESNETS:
DEFORM_MODULATED: false
DEFORM_NUM_GROUPS: 1
DEFORM_ON_PER_STAGE:- false
- false
- false
- false
DEPTH: 50
NORM: FrozenBN
NUM_GROUPS: 1
OUT_FEATURES: - res5
RES2_OUT_CHANNELS: 256
RES5_DILATION: 1
STEM_OUT_CHANNELS: 64
STRIDE_IN_1X1: true
WIDTH_PER_GROUP: 64
RETINANET:
BBOX_REG_LOSS_TYPE: smooth_l1
BBOX_REG_WEIGHTS: &id002 - 1.0
- 1.0
- 1.0
- 1.0
FOCAL_LOSS_ALPHA: 0.25
FOCAL_LOSS_GAMMA: 2.0
IN_FEATURES: - p3
- p4
- p5
- p6
- p7
IOU_LABELS: - 0
- -1
- 1
IOU_THRESHOLDS: - 0.4
- 0.5
NMS_THRESH_TEST: 0.5
NORM: ‘’
NUM_CLASSES: 80
NUM_CONVS: 4
PRIOR_PROB: 0.01
SCORE_THRESH_TEST: 0.05
SMOOTH_L1_LOSS_BETA: 0.1
TOPK_CANDIDATES_TEST: 1000
ROI_BOX_CASCADE_HEAD:
BBOX_REG_WEIGHTS: - &id001
- 10.0
- 10.0
- 5.0
- 5.0
- 20.0
- 20.0
- 10.0
- 10.0
- 30.0
- 30.0
- 15.0
- 15.0
IOUS:
- 0.5
- 0.6
- 0.7
ROI_BOX_HEAD:
BBOX_REG_LOSS_TYPE: smooth_l1
BBOX_REG_LOSS_WEIGHT: 1.0
BBOX_REG_WEIGHTS: *id001
CLS_AGNOSTIC_BBOX_REG: false
CONV_DIM: 256
FC_DIM: 1024
NAME: ‘’
NORM: ‘’
NUM_CONV: 0
NUM_FC: 0
POOLER_RESOLUTION: 14
POOLER_SAMPLING_RATIO: 0
POOLER_TYPE: ROIAlignV2
SMOOTH_L1_BETA: 0.0
TRAIN_ON_PRED_BOXES: false
ROI_HEADS:
BATCH_SIZE_PER_IMAGE: 512
IN_FEATURES: - res4
IOU_LABELS: - 0
- 1
IOU_THRESHOLDS: - 0.5
NAME: Res5ROIHeads
NMS_THRESH_TEST: 0.5
NUM_CLASSES: 80
POSITIVE_FRACTION: 0.25
PROPOSAL_APPEND_GT: true
SCORE_THRESH_TEST: 0.05
ROI_KEYPOINT_HEAD:
CONV_DIMS: - 512
- 512
- 512
- 512
- 512
- 512
- 512
- 512
LOSS_WEIGHT: 1.0
MIN_KEYPOINTS_PER_IMAGE: 1
NAME: KRCNNConvDeconvUpsampleHead
NORMALIZE_LOSS_BY_VISIBLE_KEYPOINTS: true
NUM_KEYPOINTS: 17
POOLER_RESOLUTION: 14
POOLER_SAMPLING_RATIO: 0
POOLER_TYPE: ROIAlignV2
ROI_MASK_HEAD:
CLS_AGNOSTIC_MASK: false
CONV_DIM: 256
NAME: MaskRCNNConvUpsampleHead
NORM: ‘’
NUM_CONV: 0
POOLER_RESOLUTION: 14
POOLER_SAMPLING_RATIO: 0
POOLER_TYPE: ROIAlignV2
RPN:
BATCH_SIZE_PER_IMAGE: 256
BBOX_REG_LOSS_TYPE: smooth_l1
BBOX_REG_LOSS_WEIGHT: 1.0
BBOX_REG_WEIGHTS: *id002
BOUNDARY_THRESH: -1
CONV_DIMS: - -1
HEAD_NAME: StandardRPNHead
IN_FEATURES: - res4
IOU_LABELS: - 0
- -1
- 1
IOU_THRESHOLDS: - 0.3
- 0.7
LOSS_WEIGHT: 1.0
NMS_THRESH: 0.7
POSITIVE_FRACTION: 0.5
POST_NMS_TOPK_TEST: 1000
POST_NMS_TOPK_TRAIN: 2000
PRE_NMS_TOPK_TEST: 6000
PRE_NMS_TOPK_TRAIN: 12000
SMOOTH_L1_BETA: 0.0
SEM_SEG_HEAD:
COMMON_STRIDE: 4
CONVS_DIM: 128
IGNORE_VALUE: 255
IN_FEATURES: - p2
- p3
- p4
- p5
LOSS_WEIGHT: 1.0
NAME: SemSegFPNHead
NORM: GN
NUM_CLASSES: 54
WEIGHTS: /path/to/checkpoint_file
YOLOF:
BOX_TRANSFORM:
ADD_CTR_CLAMP: true
BBOX_REG_WEIGHTS:- 1.0
- 1.0
- 1.0
- 1.0
CTR_CLAMP: 32
DECODER:
ACTIVATION: ReLU
CLS_NUM_CONVS: 2
IN_CHANNELS: 512
NORM: BN
NUM_ANCHORS: 5
NUM_CLASSES: 80
PRIOR_PROB: 0.01
REG_NUM_CONVS: 4
DETECTIONS_PER_IMAGE: 100
ENCODER:
ACTIVATION: ReLU
BACKBONE_LEVEL: res5
BLOCK_DILATIONS: - 2
- 4
- 6
- 8
BLOCK_MID_CHANNELS: 128
IN_CHANNELS: 2048
NORM: BN
NUM_CHANNELS: 512
NUM_RESIDUAL_BLOCKS: 4
LOSSES:
BBOX_REG_LOSS_TYPE: giou
FOCAL_LOSS_ALPHA: 0.25
FOCAL_LOSS_GAMMA: 2.0
MATCHER:
TOPK: 4
NEG_IGNORE_THRESHOLD: 0.7
NMS_THRESH_TEST: 0.6
POS_IGNORE_THRESHOLD: 0.15
SCORE_THRESH_TEST: 0.05
TOPK_CANDIDATES_TEST: 1000
OUTPUT_DIR: output/yolof/R_50_C5_1x
SEED: -1
SOLVER:
AMP:
ENABLED: false
BACKBONE_MULTIPLIER: 0.334
BASE_LR: 0.12
BIAS_LR_FACTOR: 1.0
CHECKPOINT_PERIOD: 2500
CLIP_GRADIENTS:
CLIP_TYPE: value
CLIP_VALUE: 1.0
ENABLED: false
NORM_TYPE: 2.0
GAMMA: 0.1
IMS_PER_BATCH: 64
LR_SCHEDULER_NAME: WarmupMultiStepLR
MAX_ITER: 22500
MOMENTUM: 0.9
NESTEROV: false
REFERENCE_WORLD_SIZE: 0
STEPS:
- 15000
- 20000
WARMUP_FACTOR: 0.00066667
WARMUP_ITERS: 1500
WARMUP_METHOD: linear
WEIGHT_DECAY: 0.0001
WEIGHT_DECAY_BIAS: 0.0001
WEIGHT_DECAY_NORM: 0.0
TEST:
AUG:
ENABLED: false
FLIP: true
MAX_SIZE: 4000
MIN_SIZES:- 400
- 500
- 600
- 700
- 800
- 900
- 1000
- 1100
- 1200
DETECTIONS_PER_IMAGE: 100
EVAL_PERIOD: 0
EXPECTED_RESULTS: []
KEYPOINT_OKS_SIGMAS: []
PRECISE_BN:
ENABLED: false
NUM_ITER: 200
VERSION: 2
VIS_PERIOD: 0
[04/23 11:13:47 detectron2]: Full config saved to output/yolof/R_50_C5_1x\config.yaml
[04/23 11:13:47 d2.utils.env]: Using a generated random seed 47610603
[04/23 11:13:53 d2.engine.defaults]: Model:
YOLOF(
(backbone): ResNet(
(stem): BasicStem(
(conv1): Conv2d(
3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
)
(res2): Sequential(
(0): BottleneckBlock(
(shortcut): Conv2d(
64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv1): Conv2d(
64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv2): Conv2d(
64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv3): Conv2d(
64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
)
(1): BottleneckBlock(
(conv1): Conv2d(
256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv2): Conv2d(
64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv3): Conv2d(
64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
)
(2): BottleneckBlock(
(conv1): Conv2d(
256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv2): Conv2d(
64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv3): Conv2d(
64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
)
)
(res3): Sequential(
(0): BottleneckBlock(
(shortcut): Conv2d(
256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv1): Conv2d(
256, 128, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv2): Conv2d(
128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv3): Conv2d(
128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
)
(1): BottleneckBlock(
(conv1): Conv2d(
512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv2): Conv2d(
128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv3): Conv2d(
128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
)
(2): BottleneckBlock(
(conv1): Conv2d(
512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv2): Conv2d(
128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv3): Conv2d(
128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
)
(3): BottleneckBlock(
(conv1): Conv2d(
512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv2): Conv2d(
128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv3): Conv2d(
128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
)
)
(res4): Sequential(
(0): BottleneckBlock(
(shortcut): Conv2d(
512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
(conv1): Conv2d(
512, 256, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(1): BottleneckBlock(
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(2): BottleneckBlock(
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(3): BottleneckBlock(
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(4): BottleneckBlock(
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(5): BottleneckBlock(
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
)
(res5): Sequential(
(0): BottleneckBlock(
(shortcut): Conv2d(
1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=2048, eps=1e-05)
)
(conv1): Conv2d(
1024, 512, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv2): Conv2d(
512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv3): Conv2d(
512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=2048, eps=1e-05)
)
)
(1): BottleneckBlock(
(conv1): Conv2d(
2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv2): Conv2d(
512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv3): Conv2d(
512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=2048, eps=1e-05)
)
)
(2): BottleneckBlock(
(conv1): Conv2d(
2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv2): Conv2d(
512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv3): Conv2d(
512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=2048, eps=1e-05)
)
)
)
)
(encoder): DilatedEncoder(
(lateral_conv): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1))
(lateral_norm): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(fpn_conv): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(fpn_norm): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(dilated_encoder_blocks): Sequential(
(0): Bottleneck(
(conv1): Sequential(
(0): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv2): Sequential(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv3): Sequential(
(0): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
(1): Bottleneck(
(conv1): Sequential(
(0): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv2): Sequential(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(4, 4), dilation=(4, 4))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv3): Sequential(
(0): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
(2): Bottleneck(
(conv1): Sequential(
(0): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv2): Sequential(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(6, 6), dilation=(6, 6))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv3): Sequential(
(0): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
(3): Bottleneck(
(conv1): Sequential(
(0): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv2): Sequential(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(8, 8), dilation=(8, 8))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(conv3): Sequential(
(0): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
)
)
(decoder): Decoder(
(cls_subnet): Sequential(
(0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
)
(bbox_subnet): Sequential(
(0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(7): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(8): ReLU(inplace=True)
(9): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(10): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(11): ReLU(inplace=True)
)
(cls_score): Conv2d(512, 400, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bbox_pred): Conv2d(512, 20, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(object_pred): Conv2d(512, 5, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(anchor_generator): DefaultAnchorGenerator(
return self.load(path, checkpointables=[])
File “e:\anacondalib\detectron2-master\detectron2-master\detectron2\checkpoint\detection_checkpoint.py”, line 53, in load
ret = super().load(path, *args, **kwargs)
File “D:\Anaconda3\envs\detectron2\lib\site-packages\fvcore\common\checkpoint.py”, line 153, in load
assert os.path.isfile(path), “Checkpoint {} not found!”.format(path)
AssertionError: Checkpoint /path/to/checkpoint_file not found!
接下来我们逐步实现yolof能够跑起来
首先我们安装labelme
这一部分参考来自(84条消息) Labelme安装及使用教程_Marlowee的博客-CSDN博客_labelme安装 https://blog.csdn.net/weixin_43427721/article/details/107122775 “(84条消息) Labelme安装及使用教程_Marlowee的博客-CSDN博客_labelme安装”
7.1报错与解决
报错:KeyError: “Dataset ‘test’ is not registered! Available datasets are: coco_2014_train, coco_2014_val, coco_2014_minival, coco_2014_minival_100, coco_2014_valminusminival, coco_2017_tra
in, coco_2017_val, coco_2017_test, coco_2017_test-dev, coco_2017_val_100, keypoints_coco_2014_train, keypoints_coco_2014_val, keypoints_coco_2014_minival, keypoints_coco_2014_valminus
minival, keypoints_coco_2014_minival_100, keypoints_coco_2017_train, keypoints_coco_2017_val, keypoints_coco_2017_val_100, coco_2017_train_panoptic_separated, coco_2017_train_panoptic
_stuffonly, coco_2017_train_panoptic, coco_2017_val_panoptic_separated, coco_2017_val_panoptic_stuffonly, coco_2017_val_panoptic, coco_2017_val_100_panoptic_separated, coco_2017_val_1
00_panoptic_stuffonly, coco_2017_val_100_panoptic, lvis_v1_train, lvis_v1_val, lvis_v1_test_dev, lvis_v1_test_challenge, lvis_v0.5_train, lvis_v0.5_val, lvis_v0.5_val_rand_100, lvis_v
0.5_test, lvis_v0.5_train_cocofied, lvis_v0.5_val_cocofied, cityscapes_fine_instance_seg_train, cityscapes_fine_sem_seg_train, cityscapes_fine_instance_seg_val, cityscapes_fine_sem_se
g_val, cityscapes_fine_instance_seg_test, cityscapes_fine_sem_seg_test, cityscapes_fine_panoptic_train, cityscapes_fine_panoptic_val, voc_2007_trainval, voc_2007_train, voc_2007_val, voc_2007_test, voc_2012_trainval, voc_2012_train, voc_2012_val, ade20k_sem_seg_train, ade20k_sem_seg_val”
报错OS Error
OSError: [WinError 1455] 页面文件太小,无法完成操作。
解决方法:
dataloader.test = L(build_data_loader)(
dataset=L(torchvision.datasets.ImageNet)(
root=”${…train.dataset.root}”,
split=”val”,
transform=L(T.Compose)(
transforms=[
L(T.Resize)(size=256),
L(T.CenterCrop)(size=224),
T.ToTensor(),
L(T.Normalize)(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
]
),
),
batch_size=256 // 8,
num_workers=4, #修改此处的num_workers=0即可
training=False,
)
其他报错:
[04/25 16:25:24 d2.engine.train_loop]: Starting training from iteration 0
Install mish-cuda to speed up training and inference. More importantly, replace the naive Mish with MishCuda will give a ~1.5G memory saving during training.
Traceback (most recent call last):
File “
File “D:\Anaconda3\envs\detectron2\lib\multiprocessing\spawn.py”, line 116, in spawn_main
exitcode = _main(fd, parent_sentinel)
File “D:\Anaconda3\envs\detectron2\lib\multiprocessing\spawn.py”, line 125, in _main
prepare(preparation_data)
File “D:\Anaconda3\envs\detectron2\lib\multiprocessing\spawn.py”, line 236, in prepare
_fixup_main_from_path(data[‘init_main_from_path’])
File “D:\Anaconda3\envs\detectron2\lib\multiprocessing\spawn.py”, line 287, in _fixup_main_from_path
main_content = runpy.run_path(main_path,
File “D:\Anaconda3\envs\detectron2\lib\runpy.py”, line 265, in run_path
return _run_module_code(code, init_globals, run_name,
File “D:\Anaconda3\envs\detectron2\lib\runpy.py”, line 97, in _run_module_code
_run_code(code, mod_globals, init_globals,
File “D:\Anaconda3\envs\detectron2\lib\runpy.py”, line 87, in _run_code
exec(code, run_globals)
File “E:\anacondalib\detectron2\YOLOF-master\YOLOF-master\tools\train_net.py”, line 47, in
from torch.contrib._tensorboard_vis import visualize
File “D:\Anaconda3\envs\detectron2\lib\site-packages\torch\contrib_tensorboard_vis.py”, line 17, in
raise ImportError(“TensorBoard visualization of GraphExecutors requires having “
ImportError: TensorBoard visualization of GraphExecutors requires having TensorFlow installed
现阶段(当前)遇到的问题:
yolof可以跑起来,但是目前的问题在于识别结果框的visualize可视化出了一些问题,yolof这一块跑起来以后目前无法做出成功的可视化框。